购物车
 您的购物车当前为空
您的购物车当前为空

人工智能释放药物潜力,快速简化大规模数据筛选




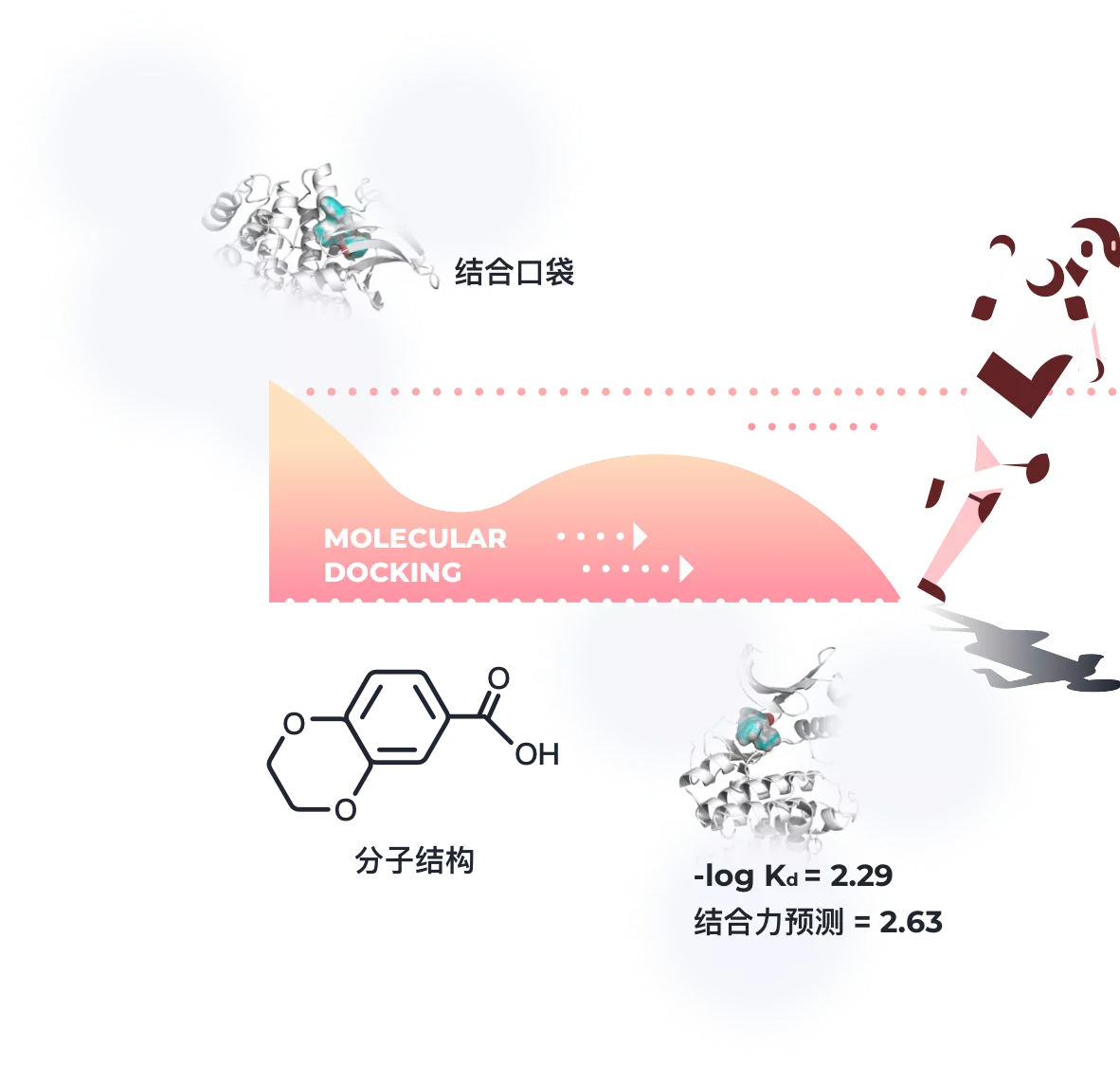
虚拟筛选的成功与否与化合物库数量紧密相关,更大的化合物库意味着更多样化的化学空间,从而提高筛选到高结合力化合物的可能性。然而基于分子对接的虚拟筛选需要大量的计算资源,使用传统的硬件平台筛选亿级别的数据库是不现实的,因此需要采用基于人工智能的新方法,在不影响准确性的情况下大大提高虚拟筛选进程。
TargetMol团队开发了基于图神经网络的 PLANET 深度学习模型。PLANET 模型采用靶 蛋白结合口袋的三维结构以及配体分子的二维结构作为输入即可预测给定配体分子的靶蛋白亲合性,无需执行分子对接中耗时的 构象采样过程,因此可以大大加速虚拟筛选。在 LIT-PCBA 等标准测试集上获得的结果显示:PLANET方法在虚拟筛选任务中的准确 率与分子对接方法GLIDE 相当,但是完成任务的速度比 GLIDE 快 1000 倍以上!


结合PLANET 模型的优势,上海陶术 CADD 团队在虚拟筛选流程中采用PLANET 先进行初步筛选,然后再对排名靠前的1~5% 化合物采用传统分子对接方法进行复筛。这种技术流程一方面大幅提高了虚拟筛选能够处理的化合物库规模,另一方面,也能保持预测精度,同时产生客户关心的化合物与靶标蛋白的具体作用模式。


| 靶点名称 | 已知活性 分子数量 | 富集因子(Enrichment factor) | ||||
|---|---|---|---|---|---|---|
| EF 0.1% | EF 1% | EF 5% | EF 10% | |||
| BRD4 | 5739 | 29.4 | 23.7 | 10.5 | 6.5 | |
| HER2 | 2080 | 38.5 | 20.9 | 10.1 | 6.4 | |
| BCL2 | 946 | 540.2 | 80.6 | 17.4 | 8.9 | |
| ACE2 | 15 | 333.3 | 60 | 13.6 | 6.7 | |
| BCL2 | 23 | 695.6 | 73.9 | 18.3 | 9.6 | |
【注】在该验证中,选取在 ChEMBL 数据库中收录的在各靶点上活性好于 10 μM 的化合物作为阳性化合物,考察使用 PLANET 算法的可靠性。
结果显示:PLANET 面对不同来源、不同类型的靶标,均能以较高的成功率筛选出活性化合物,充分展现出了其作为超大规模虚拟筛选实用工具的价值。
 嗨!有任何问题?点我咨询
嗨!有任何问题?点我咨询
版权所有©2015-2026 TargetMol Chemicals Inc.保留所有权利.
沪ICP备20019793号-4 | 沪公网安备 31010602006700号 | 沪(静)应急管危经许[2024]203441
| 沪(静)应急管危经许[2024]203441